
ONNC (Open Neural Network Compiler) is a retargetable compilation framework designed specifically for proprietary deep learning accelerators. Its software architecture expedites porting ONNC to any Deep Learning Accelerator (DLA) design that supports ONNX (Open Neural Network Exchange) operators. ONNC guarantees executability across every DLA by means of transforming ONNX models into DLA-specific binary forms and leveraging the intermediate representation (IR) design of ONNX along with effective algorithms to eliminate the overhead of data movement. ONNC is the first open source compiler available for NVDLA-based hardware designs. Its NVDLA backend can compile a model into an executable NVDLA Loadable file. Integrating ONNC with the NVDLA software stack opens up opportunities for developers and researchers to explore the NVDLA-based inference design at the system level.

How It Works
Modular Framework to Ensure Executability in an easy way
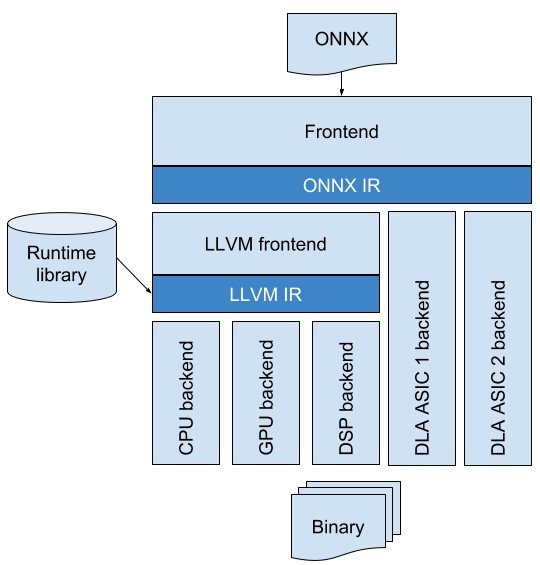
ONNC is integrated with the LLVM bitcode runtime and compiler. If a DLA already supports the LLVM compiler, it can be connected to ONNC seamlessly. This helps most CPUs, GPUs, and DSPs ported to ONNC in a very short time. On the other hand, if a DLA has unique computation features and is not compatible to LLVM, ONNC also provides a modular framework to speed up the compiler development. DLA vendors can quickly customize an ONNC backend from a so called “vanilla” backend, which already provides some necessary optimization algorithms.
Reusable Compiler Optimizations
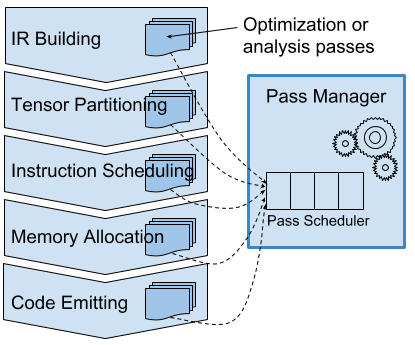
Two of ONNC’s contributions are dividing the AI compilation into several clear phases and giving the corresponding APIs for algorithm development. There are five phases carefully defined, each of which is focused on a particular compiler problem: IR building, partitioning, scheduling, allocation, and code emitting. ONNC also provides a series of optimization algorithms ready for use. They are general and reusable, including tensor selection, tensor liveness analysis, linear scan local memory allocation, etc. ONNC’s pass manager is flexible and similar to LLVM’s. AI researchers and engineers who are familiar with LLVM can intuitively contribute their general or target-specific optimization algorithms to ONNC.
Download
Get everything you need on our GitHub page.
GitHubGetting Started
Introduction
There are three different types of developers in the community: porters, compiler engineers and testers. We provide three different sub-projects for these developers. In the ONNC project, there are three sub-projects: umbrella, onnc and regression.
The Umbrella project
The umbrella project offers a simple way for users and porters to build and install ONNC applications. It collects dependent 3rd party libraries and provides scripts to build them. Porters can easily understand how does ONNC connect to the outside world and ONNC’s assumption of the surroundings. It helps porters to figure out the best approach to deploy on their system in a short time.
The umbrella project also provides a minimal environment for users. Users can easily boot up ONNC in their system from the Umbrella project.
The ONNC project
The ONNC project provides a modern compiler framework for ONNX format. We define a two-level intermediate representations (IR) for both target-independent and target-dependent compiler analysis and optimization. It also provides an iterative pass manager to help target-dependent optimization algorithms figure out the best parameters via try-and-error. Our modular target device selector helps DLA vendors to port ONNC on their devices in a simple way.
The Regression Test project
The Regresson Test project is a placeholder of full regression tests. It may spends days to run regression test once. Before a major release, all tests in the full regression should be passed.
The most simple way to get ONNC started on your system is follow the instructions of the umbrella project
News
Events
- Jun. 29 2023 - Skymizer Achieves Top-Tier Performance in MLPerf® Tiny v1.1 Benchmarks
- May10, 2023 / Taipei, Taiwan ISES Taiwan 2023
- Apr19, 2023 / Taipei, Taiwan AI EXPO Twiwan 2023
- May 30 ISCA2020 Tutorial: ONNC Compiler Porting and Optimization for NVDLA-Based Neural Network Inference Engines
- Oct 12 Micro2019 Tutorial: ONNC Compiler Porting and Optimization for NVDLA-Based Neural Network Inference Engines
Tutorials
Getting Involved
ONNC is an often release project, any ideas for developing ONNC are welcome.